


Basis aller heutigen Künstlichen Intelligenz sind bekanntlich Algorithmen. Diese sind in den letzten Jahren in zunehmendem Ausmaß in den Fokus der öffentlichen Wahrnehmung gerückt. Dabei schwankt der Grad an thematischer Souveränität und Güte der einzelnen Wortmeldungen aus Presse, Politik und Gesellschaft teils erheblich. Headlines zum Thema Künstliche Intelligenz können zuweilen Verwirrung stiften: „Männer sind leichter durch Künstliche Intelligenz zu ersetzen als Frauen“, titelt beispielsweise die Neue Zürcher Zeitung. „Künstliche Intelligenz ist sehr viel gefährlicher als Atomwaffen“, lässt das Handelsblatt verlauten. Und RP online überrascht mit „Künstliche Intelligenz aus Japan - Roboterfrau wird Krankenschwester“. Was unter den Akteuren der Debatte um KI allgemein als gesetzt angesehen wird, ist, dass Algorithmen massiv in unser aller Leben eingreifen werden - oder das sogar schon tun. Das soll hier gar nicht bestritten werden. Trotzdem muss man sagen: Wirklich fundiertes Wissen fehlt fast allen, die sich zu diesem Thema zu Wort melden. Dessen ungeachtet fühlen sich viele zu Urteilen inspiriert, die über eine sorgenfreie Zukunft bis hin zum vollständigen Untergang der Menschheit reichen. Angesichts dieser lückenhaften Aufklärung über ein Thema, das imstande ist, gleichzeitig so viel kollektive Angst und Hoffnung auszulösen, ist es durchaus nicht verwunderlich, dass ein stark ausgeprägter Reflex der Debatte die laute Forderung nach Transparenz ist. Das, was da kommt, egal was es macht, egal für wen, es soll, nein es muss - Unbedingt! - transparent bleiben. Denn Transparenz ist Basis unserer freiheitlichen, demokratischen Grundordnung und die gilt es zu schützen - soweit sind sich (fast) alle einig. Doch was meinen wir eigentlich, wenn wir von Transparenz in Bezug auf Algorithmen sprechen?
Um das zu klären, müssen zunächst noch einige andere Fragen grundsätzlich erörtert werden. Das ist angesichts der angesprochenen, teils desolaten, Informationslage dringend geboten.
Was ist ursächlich für den aktuellen KI-Boom?
Zum aktuellen KI-Boom gibt es zwei populäre Hypothesen. Die erste ist: Die Rechenleistung ist in jüngster Zeit so stark angestiegen, dass bestimmte Algorithmen, die es früher nicht waren, jetzt auf einmal berechenbar sind. Hierzu lässt sich sagen: Wahr ist, dass die Rechenleistung rasant gestiegen ist und auch noch weiter steigen wird. Unwahr ist dagegen, dass dies automatisch zu Künstlicher Intelligenz führt. Damit das so wäre, müssten in diesen sehr leistungsfähigen Computern ähnliche Dinge passieren, wie in einem Gehirn. Wer in den Debatten schon einmal den Begriff „neuronales Netz“ aufgeschnappt hat, dem scheint das auch durchaus naheliegend. Es könnte ja sein, dass man diese „neuronalen Netze“ nur möglichst groß aufziehen muss, mit ganz viel Rechenleistung ausstatten also, und dann haben wir Künstliche Intelligenz, genauso gut wie ein Gehirn - oder sogar besser. Das wäre allerdings ein Irrtum. Ein neuronales Netz bildet in keiner Weise die Funktionsweise eines Gehirns ab. Über diese wissen wir faszinierenderweise noch immer sehr, sehr wenig. Das mit EU-Mitteln geförderte „Human Brain Project“ versucht aktuell, diesen Umstand zu ändern. Nennenswerte Erfolge sind bis jetzt nicht erzielt worden. Zusammengefasst: Rechenleistung ist nicht für das verantwortlich, was wir heute KI nennen.
Die zweite Hypothese besagt, dass es heutzutage neuartige Algorithmen gebe, die viel elaborierter und technisch raffinierter seien, als zum Beispiel die Schachcomputer der 60er Jahre - und deshalb eben auch viel intelligenter. In dieser Hypothese schwingt, so könnte man sagen, die Sehnsucht mit, Algorithmen zu glorifizieren und ein wenig vielleicht auch der etwas naive Glaube an eine Art Weltformel. Die ist allerdings bislang noch nicht gefunden worden. Tatsächlich muss man hier ganz nüchtern bleiben und zugeben: Das, was an technologisch-methodischen Grundbausteinen hinter heutiger KI steckt, sind zwei verschiedene Verfahren, die vom Grundprinzip her seit einem gewissen Herrn Gauß bekannt sind. Einerseits sind das Verfahren zur Mustererkennung und andererseits Verfahren zur Suche, bzw. zur Optimierung. Algorithmen zur Mustererkennung setzen dabei auf historischen Datensätzen auf, finden darin Zusammenhänge und erlauben dadurch Vorhersagen oder Extrapolation. Algorithmen zur Suche und Optimierung hingegen, können in einem großen Raum von Optionen die beste Option identifizieren. Praktisch und vom Ergebnis her können diese Algorithmen - insbesondere mit heutiger Rechenleistung - natürlich sehr mächtig sein. Trotzdem hat Mustererkennung und Suche nichts mit Denken, Bewusstsein oder Kreativität zu tun - mit allem also, was menschliche Intelligenz eigentlich ausmacht.
Ursächlich dafür, dass wir heute über KI-Systeme verfügen, die uns intelligent erscheinen, ist etwas viel, viel Banaleres: die Digitalisierung und die damit einhergehende Datafizierung. Dabei heißt „digitalisiert“ nichts Anderes, als dass ein Stück Realität in digitalen Prozessen (Software) und in Folge dessen in Daten abgebildet ist. Um sich den Zusammenhang zwischen heutiger KI und der Digitalisierung klar zu machen, ist es sinnvoll, sich das Prinzip des Datenverarbeitungsschemas vor Augen zu führen. Datenverarbeitung besteht aus drei Teilen: Eingabe - Verarbeitung - Ausgabe. In den 80er Jahren, als beispielsweise die Finanzindustrie schon teilweise digitalisiert war, sah es auf der Ein- und Ausgabenseite jeweils noch düster aus. Im Bereich Verarbeitung waren leistungsfähige Such- und Mustererkennungsalgorithmen hingegen schon bekannt und funktionierten im Prinzip ähnlich wie heute auch. Auf Basis der wenigen verfügbaren Daten und der vergleichsweise geringen Rechenleistung, konnten diese Algorithmen aber praktisch nur wenig tun: Ausdrucke über einen Nadeldrucker oder das Anzeigen von Daten auf einem Bildschirm waren beispielsweise möglich. Stark vermenschlicht ausgedrückt könnte man sagen: Algorithmen konnten damals nur einen ganz kleinen Teil der Welt wahrnehmen - und die Ergebnisse dann als Morsecode mit dem kleinen Finger nach außen geben.
Was kann KI-Technologie heute wirklich?
Das sieht heute ganz anders aus. Dramatisch mehr Bereiche unserer Welt schlagen sich mittlerweile in Daten nieder. Bewegungsmuster, Kaufverhalten, Freundschaften - um nur einige zu nennen. Gesammelt werden die Daten von Satelliten, Online-Händlern und sozialen Netzwerken. Weiterhin ist der Handlungsspielraum von Algorithmen heute deutlich größer und zwar aufgrund ihrer Einbettung in eine halbwegs digitalisierte, durch das Internet vernetzte Welt. Wo der Handlungsspielraum eines Algorithmus früher am Bildschirm oder Nadeldrucker endete, ermöglichen heute zahlreiche Schnittstellen (APIs) digitaler Systeme untereinander dem Algorithmus die Ausführung verschiedenster Aktionen, ohne dass etwa der Mensch als Mittler eine Rolle spielen würde. So können Algorithmen in ihrem heutigen Handlungsspielraum beispielsweise Flüge buchen, Autos steuern, oder Bestellungen tätigen. Diese Erweiterung ermöglicht Algorithmen hochkomplexes, teilweise selbstständig anmutendes Handeln. Als Beispiel sei hier der Algorithmus genannt, dem es gelang, die Urananreicherung im Iran zu sabotieren, indem er, heimlich eingeschleust, durch Fehlsteuerung die im Einsatz befindlichen Zentrifugen zerstörte. Diese Wirkmächtigkeit ist durchaus erstaunlich.
Trotzdem muss man sagen: An dem, was in der Mitte – der Verarbeitung – steht, hat sich seit 1988 wenig verändert, zumindest was das konzeptionelle Fähigkeitsniveau betrifft. Entscheidend ist, was auf der Eingabeseite durch die Digitalisierung erreicht wurde. Dieser Reichtum an Daten macht „einfache“ Algorithmen auf schnellen Rechnern sehr wirkungsvoll. Und das ist das ganze Geheimnis heutiger KI: Datenverfügbarkeit. Nicht Supercomputer oder die Weltformel.
Wie wird uns KI in Zukunft beeinflussen?
Wenn man genau hinsieht, fällt auf, dass erst ganz bestimmte Teile unseres Lebens von KI-Anwendungen betroffen sind. Genauer gesagt: ganz überwiegend sind die digitalisierten Bereiche des Lebens solche, die unter „Endkonsumenten-Anwendungen“einzuordnen sind. Stichwort: Google, Amazon, Facebook - alles Unternehmen oder Technologien in Branchen, die noch sehr jung sind. Betrachten wir die Gesamtwirtschaft, müssen wir einräumen, dass wir mit der Digitalisierung noch ganz am Anfang stehen. Weite Teile der Wertschöpfung sind noch völlig undigital. Das heißt, dass Kernprozesse noch nicht in Daten abgebildet sind und es somit auch keine Möglichkeit gibt, mit Algorithmen dort kognitive Arbeit zu unterstützen. Beispielsweise hat die Deutsche Bahn kein IT-System, das sagen kann, wo sich ihre Güterzüge gerade befinden. Elektronische Patientenakten gibt es bis jetzt nur bruchstückhaft. In der Zementherstellung gibt es meist keine Sensorik, die den Produktionsprozess insgesamt abbildet. Die Arbeit eines Juristen ist fast vollständig analog - auch wenn sich hier im Bereich Legal Tech einiges tut. Doch damit wir hier von Digitalisierung sprechen können, muss die tatsächliche Wertschöpfung der juristischen Arbeit ein digitales Abbild haben. Das ist im Moment nicht der Fall, denn Digitalisierung bedeutet nicht, Word zu benutzen, um einen Schriftsatz zu draften, oder eine Facebook-Seite zu pflegen.
Wirklich spannend wird KI erst dann werden, wenn Branchen mit tiefer Wertschöpfung in ihrem Kern digital werden. Medizin, Recht, Landwirtschaft oder Mobilität. Was wir bei Amazon, Facebook und Google gesehen haben, war und ist durchaus interessant, aber man kann sich sicher sein: Was uns erwartet, wenn letztgenannte Sektoren digital werden, wird alle bisherigen Entwicklungen langweilig erscheinen lassen.
Was meinen wir mit Transparenz? - Ein Praxisbeispiel
idalab hat 2016 ein Projekt für das Schulamt Berlin Tempelhof-Schöneberg realisiert. Das Thema eignet sich besonders gut, um die Frage, was wir mit Transparenz eigentlich meinen, exemplarisch zu erörtern, denn das Thema war politisch sehr sensibel. Es ging um die Festlegung von Grundschuleinzugsgebieten.
Wer in Berlin schulpflichtige Kinder hat weiß: Es gibt hier ein sogenanntes Sprengelsystem. Das heißt, dass der Wohnort die Grundschule bestimmt. Eltern haben, außer in sehr speziellen Fällen, keine Wahl, auf welche Schule sie ihr Kind schicken dürfen, es sei denn, sie üben durch Einschaltung eines Rechtsanwaltes entsprechend Druck auf das Schulamt aus. Ein unangenehmer Weg, der darüber hinaus nur den finanziell besser gestellten Eltern offensteht. Da die verschiedenen Grundschulen sich in bestimmten Qualitätsparametern stark voneinander unterscheiden, ist die Zuschneidung der Einzugsgebiete ein schwieriges Thema. Schließlich geht es um die Lebenschancen der Kinder. Und da die Anzahl der schulpflichtigen Kinder kleinräumig stark schwankt, kommt die Frage der Grundschuleinzugsgebiete jedes Jahr wieder auf den Tisch des Schulamtes.
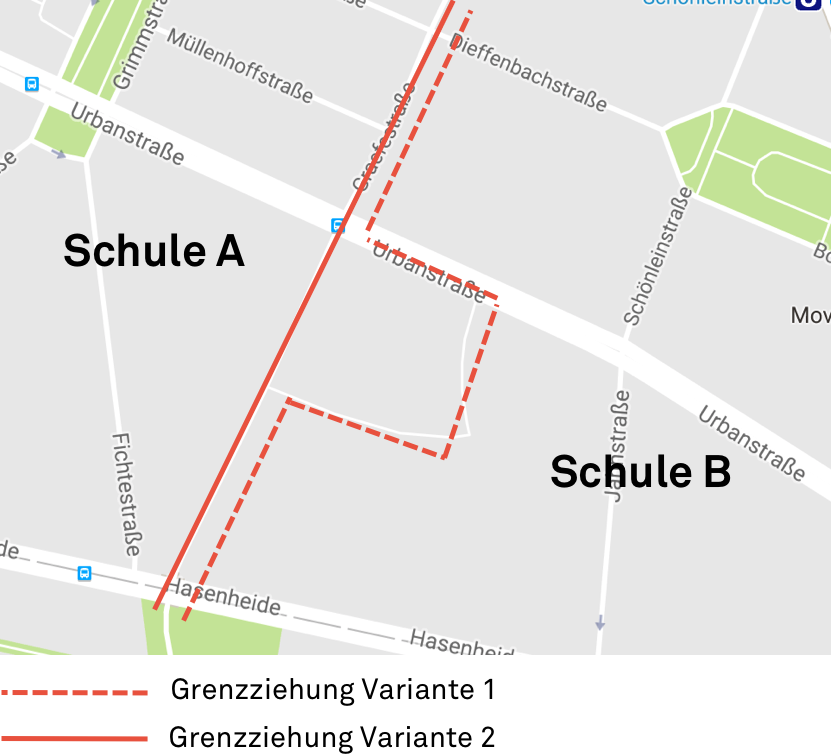
Quelle: Map data ©2018 GeoBasis-DE/BKG (©2009), Google
Wer Berlin gut kennt weiß, dass diese Bucht hier hochbrisant ist. Dort liegt die Werner-Düttmann-Siedlung, sozialer Wohnungsbau mit vermeintlich schwächer gestellten Familien. Wenn die dort wohnhaften Kinder nun zur Schule A hinzugenommen werden, wird das auf jeden Fall für Aufsehen sorgen. Genau das ist das Spannungsfeld in dem die Mitarbeiter der Berliner Schulämter Jahr für Jahr folgenschwere Entscheidungen treffen müssen. Aber damit nicht genug. Neben der sozialen Durchmischung muss auch noch die Auslastung der jeweiligen Schule und die Länge der Schulwege mit einbezogen werden. Kein Grundschulkind darf länger als 2 km zu seiner Schule laufen. Um also zu beurteilen, ob diese Bucht überhaupt zulässig ist, muss zunächst für alle Kinder, die einer Schule zugeordnet werden sollen, ein Routing durchgeführt werden. Das heißt, es geht in der Gesamtbetrachtung am Ende nicht nur um Fragen wie die der Werner-Düttmann-Siedlung, sondern darum, insgesamt, unter Einbezug aller Faktoren, die bestmögliche Aufteilung zu finden. Wie man sich leicht vorstellen kann, hat dieses Thema jedes Jahr erhebliche Ressourcen beim Schulamt gebunden. Und genau das war damals Auslöser für unsere Zusammenarbeit.
Glücklicherweise war damals, 2016, die Digitalisierung schon weit. Das heißt: Es war erstaunlich viel Material auf Seiten der Dateneingabe vorhanden. Wir hatten in computerlesbaren Daten abgebildet: Wohnadressen und Anzahl der Schüler in jedem Straßenzug, die Dichte an SGB II Leistungsempfängern in jedem Straßenzug und natürlich eine Liste aller verfügbaren Schulen und deren Kapazitäten. Auf Basis dieser Datenlage konnte ein generischer Suchalgorithmus letztendlich relativ einfach die objektiv beste Lösung finden.
Was ist die ‘objektiv beste Lösung’?
Aber Moment! Jetzt wird es interessant. Was soll das denn eigentlich bedeuten – die objektiv beste Lösung? Die objektiv beste Lösung für wen? Für das Schulamt? Für Schule A? Für Schule B? Für die Bewohner der Werner-Düttmann-Siedlung? Was heißt hier „objektiv“? Und wie lässt sich das eigentlich nachprüfen? Meine These ist: Genau das sind Fragen, auf die wir uns eigentlich konkrete, verständliche Antworten wünschen, wenn wir von Algorithmen fordern, dass sie „transparent“ sein sollen. Macht man sich das einmal klar, kann von hier aus weitergedacht werden. Wie könnte es möglich sein diese Antworten zu liefern? Durchaus kein triviales Problem.
Ist Open Source die Antwort?
Es gibt ja Stimmen, die fordern, dass der Quellcode von Algorithmen immer offengelegt werden sollte, um Transparenz zu gewährleisten. Dagegen kann man sagen, dass so auch oft wertvolle Geschäftsgeheimnisse gleich mit offengelegt werden und es fraglich ist, was das für Auswirkungen auf den Wettbewerb hätte. Doch kann man das an dieser Stelle außer Acht lassen und lediglich die Frage stellen: Befriedigt ein veröffentlichter Quellcode denn unser Bedürfnis nach Transparenz? Die Antwort darauf ist ganz klar: Nein! Wiederum am Projekt der Grundschuleinzugsgebiete betrachtet wird schnell klar warum: Bei diesem Projekt ist der Quellcode tatsächlich vollständig Open Source gewesen. Jeder konnte und kann diesen Code einsehen, Sie auch. Theoretisch ist also der Einsatz des Algorithmus gegenüber der Entscheidungsfindung des Schulamts als Fortschritt anzusehen. Die Gedankengänge der Mitarbeiter sind schließlich nicht Open Source, sondern nur auf Nachfrage erhältlich. ABER: Wer liest - und versteht - einen Open Source Code, um zu erfahren, warum sein Kind auf Schule A und nicht Schule B geschickt wird? Niemand. Oder jedenfalls nur ganz, ganz wenige. Was das angeht, ist unser Grundschuleinzugsgebiet-Projekt am Ende leider so transparent wie unser Auto oder unser Smartphone, nämlich praktisch gesehen überhaupt nicht. Deshalb ist die Veröffentlichung der Quellcodes nicht die Lösung.
Wie könnte Transparenz noch erreicht werden?
Eigentlich geht es beim Thema Transparenz im Kern um die Frage, ob uns das, was ein Algorithmus entscheidet überzeugt. Algorithmen, genauer gesagt ihre Entscheidungen, werden also dann transparent, wenn es Möglichkeiten gibt, sie zu überprüfen und ihr Ergebnis in die Kategorien „überzeugend“ oder „nicht überzeugend“ einzuordnen - und auf Basis dieser Einordnungen gegebenenfalls nachzujustieren. Wir wollen also durch Transparenz einerseits die Mittel an die Hand bekommen, Einspruch zu erheben und einzugreifen, kurz, die Möglichkeit für Kontrolle schaffen. Ob diese dann im Zweifelsfall wirklich immer ausgeübt wird, ist dann aber sicherlich andererseits gar nicht so sehr die Frage. Wichtig ist die grundsätzliche Nachvollziehbarkeit als Basis von möglicher Kontrolle, denn nur so kann ich der Richtigkeit der durch Algorithmen erzielten Ergebnisse auch grundsätzliches Vertrauen schenken.
Den Einzelfall nachvollziehbar zu machen ist aber bei Entscheidungen, die ein Algorithmus trifft, schwierig. Ein Algorithmus trifft seine Entscheidungen auf Basis sehr vieler Faktoren und einer Vielzahl an Daten, die ein Mensch kaum überblicken kann. Deshalb wird er schließlich eingesetzt. Was könnte man also tun, um die Ergebnisse des Algorithmus im Einzelfall nachvollziehbar oder überprüfbar zu machen?
Bereits bei den Such- und Optimierungsalgorithmen ist das sehr schwierig. Man könnte eigentlich höchstens andere Varianten - beispielsweise bei den Grundschuleinzugsgebieten die händische Methode des Schulamts - stichprobenartig anwenden und so überprüfen, ob man zu stark abweichenden Ergebnissen gekommen wäre.
Einfacher ist das theoretisch bei Algorithmen zur Mustererkennung. Hier würde umfassende Transparenz bestenfalls bedeuten: alle Faktoren und Einflüsse, die der Algorithmus mit einbezieht, offenzulegen. Allerdings führt das im Zweifel auch noch nicht zu Vertrauen, wie folgendes Beispiel illustrieren soll:
Sie haben bei einer Bank einen Kreditantrag gestellt, der abgelehnt wird. Sie bekommen, weil die Bank zu 100%iger Transparenz verpflichtet ist, eine Analyse, die Ihnen sagt, dass neben Ihrem Familienstand, auch Ihr Einkommen, Ihr Alter und Ihr Wohnort die Gewährung eines Kredits leider nicht zulassen. Dass eine solche Analyse Vertrauen in den Algorithmus der Bank schafft, wird wahrscheinlich niemand behaupten. Vielmehr werden Sie sich fragen: Ist das gerecht, dass ich den Kredit nicht bekommen habe, weil ich in Neukölln wohne? Schließlich habe ich in München studiert und mit Auszeichnung bestanden! Und außerdem: Ich würde dem Algorithmus schon zeigen, wie kreditwürdig ich bin - kann ich jetzt aber nicht, weil ich den Kredit nicht bekommen habe. Der Algorithmus wird also die Richtigkeit seiner Entscheidung im Einzelfall nie unter Beweis stellen! Wie sollen wir in so eine Entscheidung Vertrauen haben?
Wie schaffen wir grundsätzliches Vertrauen, wenn das im Einzelfall nicht möglich ist?
Meine These ist: Wenn wir auf der Ebene der Einzelentscheidung kein Vertrauen herstellen können – dann müssen wir uns auf das Vertrauen in den Entwicklungsprozess zurückziehen, der zum KI-System führt. Damit meine ich, dass wir Algorithmen möglicherweise ähnlich entwickeln müssten, wie heute sicherheitskritische Systeme oder Medizintechnik entwickelt wird. In einem solchen Entwicklungsprozess muss jede Designentscheidung jederzeit nachvollziehbar sein. Und die Verantwortlichen müssen für diese Designentscheidung in die Haftung genommen werden können. Das ist heute bei Algorithmen ganz überwiegend noch nicht der Fall.
Aus meiner Sicht gäbe es für einen solchen transparenten Entwicklungsprozess auch bereits zentrale Qualitätskriterien. In Bezug auf Algorithmen der Mustererkennung wären das beispielsweise die Kalibrierung auf repräsentative Daten, die keine inhärente Diskriminierung enthalten. Auch muss das Lernen aus Fehlern möglich sein, das heißt, es muss gewährleistet sein, dass ein Algorithmus, der bereits im Einsatz ist, immer wieder hinterfragt und verbessert wird.
In Bezug auf die Suchalgorithmen müsste gewährleistet sein, dass die Zielfunktionen transparent gestaltet sind. Das heißt, es sollte bekannt sein, welche Faktoren, die im Zuge einer Entscheidungsfindung durch einen Algorithmus gegeneinander abgewogen werden, wie gewichtet werden. Unterschiedliche Gewichtung führt natürlich zu unterschiedlichen Ergebnissen. Um diese Tatsache deutlich zu machen, wäre es angeraten, verschiedene Lösungsalternativen bei unterschiedlicher Gewichtung aufzuzeigen.
Die Sehnsucht nach Begründung im Einzelfall bleibt - Was tun?
Schauen wir uns zum Abschluss folgende Bilder an.
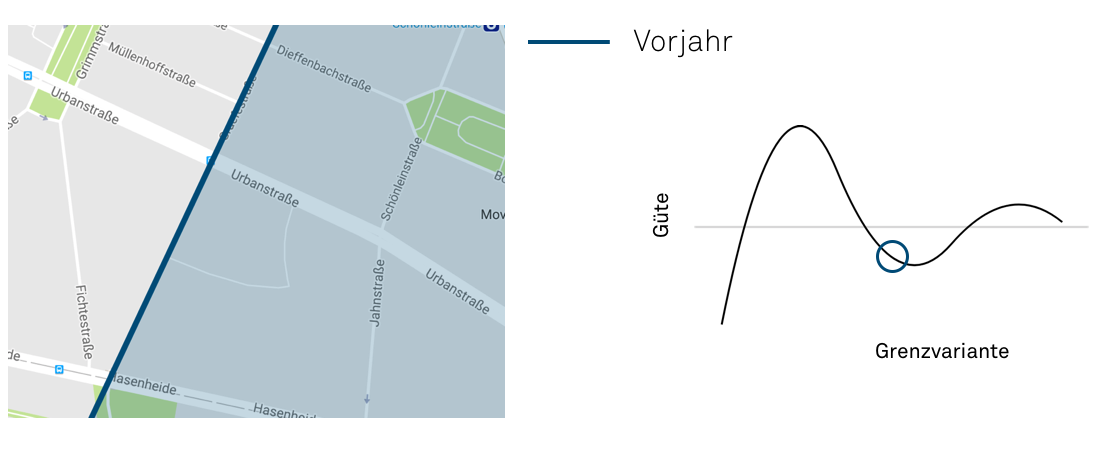
Quelle: Map data ©2018 GeoBasis-DE/BKG (©2009), Google
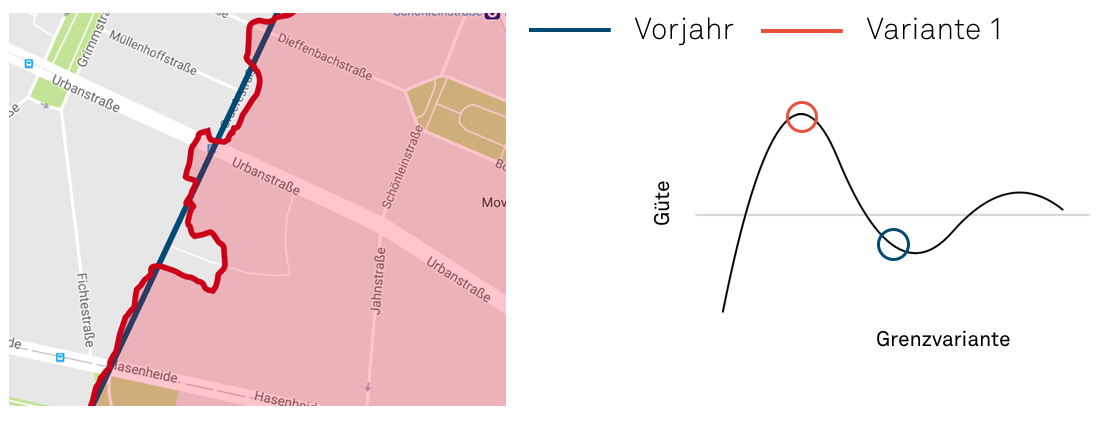
Quelle: Map data ©2018 GeoBasis-DE/BKG (©2009), Google
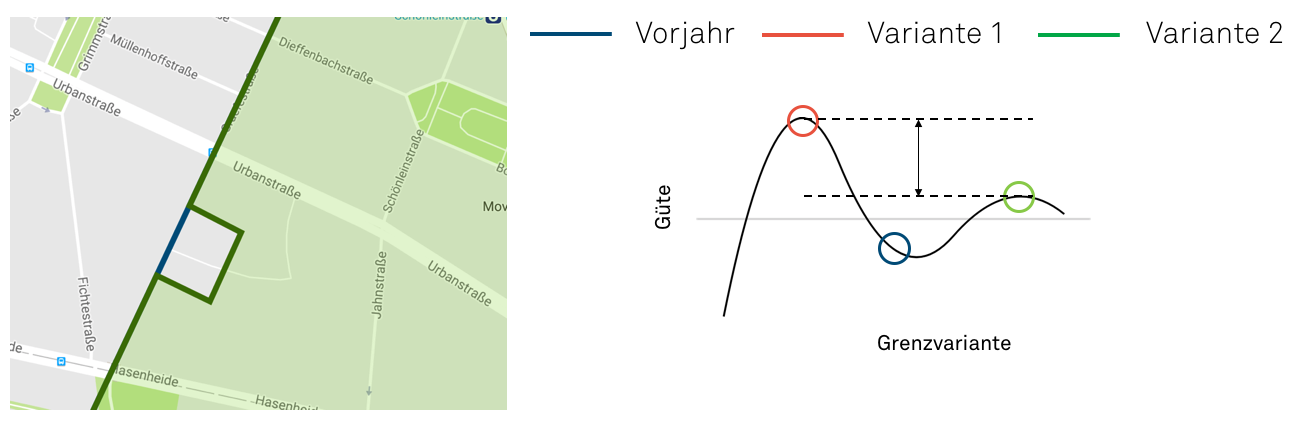
Quelle: Map data ©2018 GeoBasis-DE/BKG (©2009), Google
Die Aufteilung der Einzugsgebiete in Variante 1 ist im Einzelfall extrem gut begründbar, weil eine gerade Linie, für uns alle verständlich, zwei Bereiche voneinander trennt. Ich bin im Zweifel vielleicht verärgert darüber, dass ich Bereich A oder B zugeordnet werde, dennoch werde ich die Logik der geraden Linie höchstwahrscheinlich nicht anzweifeln. Leider ist die gerade Linie vom Standpunkt der Optimierung aus gesehen sehr schlecht.
Variante 2 ist dagegen von der Zuschneidung der Einzugsgebiete her betrachtet absolut optimal. Allerdings kann sie im Einzelfall extrem schwer begründet werden. Wie soll ich auf Basis dieser merkwürdigen Zickzacklinie glauben, dass es gerecht ist, dass mein Kind zu Schule A oder B gehen soll? Die Nerven werden auf Seiten der Eltern und auf Seiten des Schulamtes blank liegen. Das ist vorprogrammiert. Was also tun?
Die Antwort darauf liefert Variante 3. Variante 3 kann ich unter Verweis auf die gesetzlich vorgeschriebene soziale Durchmischung der Schülerschaft wunderbar begründen. Ansonsten ist die Linie gerade, was das grundsätzliche Vertrauen noch erhöhen dürfte. Und letztendlich ist Variante 3 immer noch deutlich optimaler als Variante 1, insgesamt betrachtet also das bestmögliche Ergebnis.
Ist gut begründen also wichtiger als gut entscheiden?
Meiner Ansicht nach: Ja. Algorithmen, deren Entscheidungen wir vertrauen können, sind noch wichtiger als Algorithmen, die zwar theoretisch das beste Ergebnis liefern, praktisch aber für fast alle Menschen intransparent bleiben - und deshalb nicht akzeptiert werden. Da es für Vertrauen eben nicht reicht, wenn der Entwicklungsprozess gewissen Qualitätskriterien unterliegt, brauchen wir Algorithmen, die uns in einem für uns verständlichen Narrativ nahebringen können, warum welche Entscheidungen so und nicht anders getroffen wurden. Dafür müssen wir es im Zweifel auch hinnehmen, dass dieses Mehr an Vertrauen zulasten der Optimalität geht.
Diese verständlichen Narrative, eigentlich also die Fähigkeit eine Geschichte zu erzählen, müssen wir den Algorithmen aber selbst beibringen. Daher ist die Bewusstwerdung über die Sehnsucht nach Begründung der erste Schritt. Der zweite Schritt ist es dann, diese Sehnsucht in der Entwicklung eines Algorithmus bereits mitzudenken. Dies ist durchaus auch eine mathematisch-algorithmische Herausforderung ganz neuer Art. Stellen wir uns dieser aber nicht, bringen Algorithmen keine Erleichterung, sondern Misstrauen und Zwiespalt. Anders ausgedrückt: Kein Prozess, kein Produkt, keine Wertschöpfung wird je zufriedenstellend optimiert werden, wenn das Bedürfnis des Menschen nach Verstehen dabei nicht im Mittelpunkt bleibt.

